A good while ago at a conference, I got into a debate over the usefulness of TLS (thread-local storage of variables) in performance critical code. Allegedly TLS should be too slow for practical uses, especially for shared libraries.
TLS can be quite useful for context sensitive APIs, here’s a simple example:
push_default_background (COLOR_BLUE);
auto w = create_colorful_widget(); // gets blue background
pop_default_background();For a single threaded program, the above push/pop functions can keep the default background color for widget creation in a static variable. But to allow concurrent widget creation from multiple threads, that variable will have to be managed per-thread, so it needs to become a thread local variable.
Another example is GSlice, a memory allocator that keeps per-thread allocation caches (magazines) for fast successive allocation and deallocation of equally sized memory chunks. While operating within the cache size, only thread local data needs to be accessed to release and reallocate memory chunks. So no other synchronization operations with other threads are needed that could degrade performance.
GCC (I’m using 4.9.1 here), GLibc (2.19), et all have seen a lot of improvements since, so I thought I’d dig out an old benchmark and evaluate how TLS does nowadays. To test the shared library case in particular, I’ve written the benchmark as a patch against Rapicorn and posted it here: thread-local-storage-benchmark.diff.
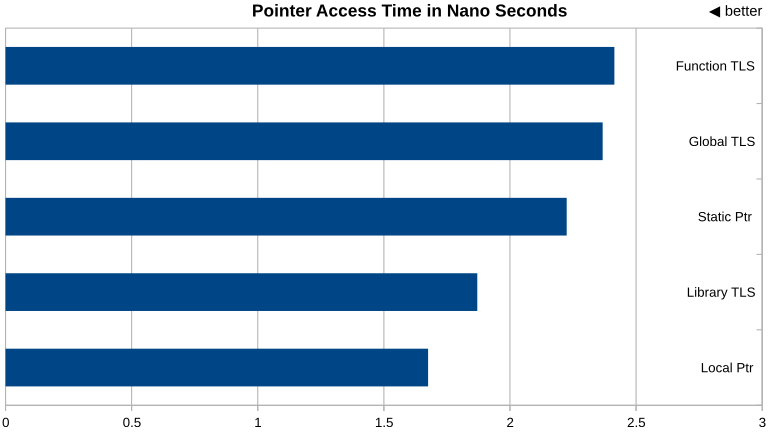
The following table lists the best results from multiple benchmark runs. The numbers shown are the times for 2 million function calls to fetch a (TLS) pointer of each kind (plus some benchmarking overhead), on a Core-i7 CPU @ 2.80GHz in 64bit mode:
Local pointer access (no TLS): 0.003351 seconds Shared library TLS pointer access: 0.003741 seconds Static pointer access (no TLS): 0.004450 seconds Executable global TLS pointer access: 0.004735 seconds Executable function-local TLS pointer access: 0.004828 seconds
The greatest timing variation in these numbers is within thirty percent (30.6%). In realistic scenarios, the time needed for pointer accesses is influenced by a lot of other more dominant factors, like code locality and data cache faults.
So while it might have been true that TLS had some performance impacts in its infancy, with a modern tool chain on AMD64 Linux, performance is definitely not an issue with the use of thread-local variables.
Here is the count out in nano seconds per pointer access call:
Let me know if there are other platforms that don’t perform as well.