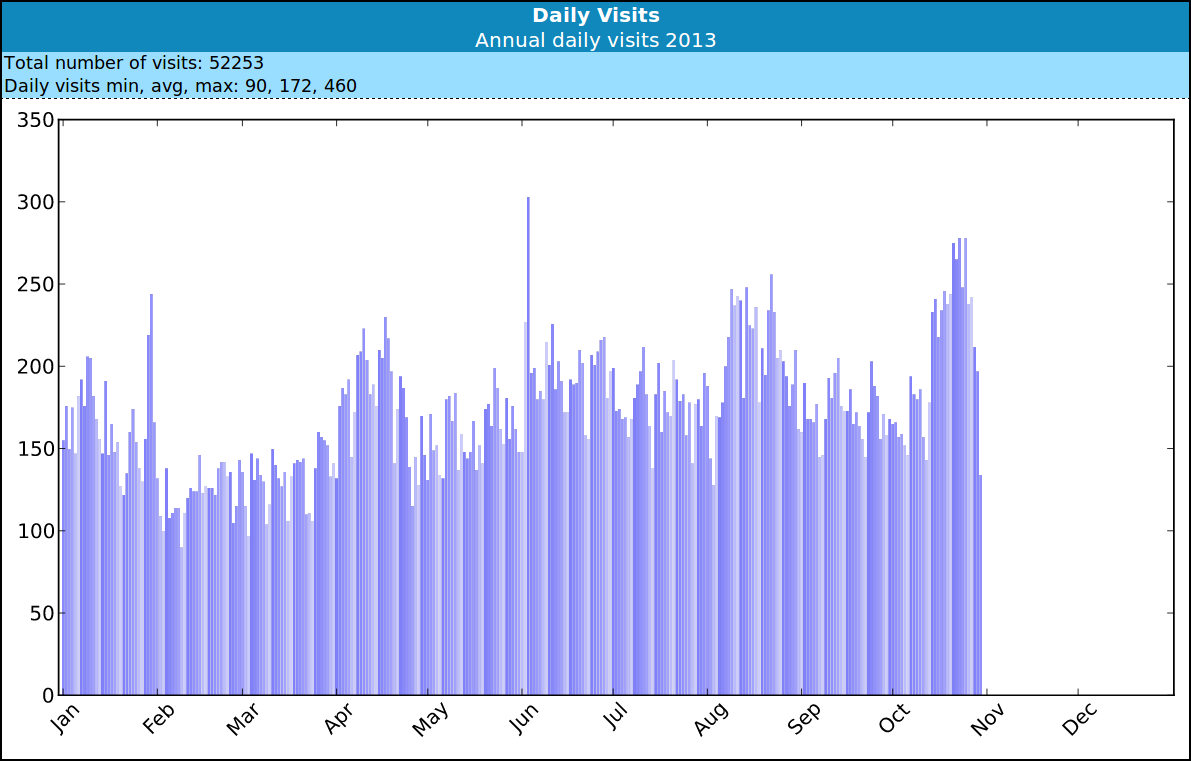
During recent weeks, I’ve started to create a new tool "Tobin" to generate website statistics for a number of sites I’m administrating or helping with. I’ve used programs like Webalizer, Visitors, Google Analytics and others for a long time, but there’re some correlations and relationships hidden in web server log files that are hard or close to impossible to visualize with these tools.
The Javascript injections required by Google Analytics are not always acceptable and fall short of accounting for all traffic and transfer volume. Also some of the log files I’m dealing with are orders of magnitudes larger than available memory, so the processing and aggregation algorithms used need to be memory efficient.
Here is what Tobin currently does:
-
Input records are read and sorted on disk, inputs are filtered for a specific year.
-
A 30 minute window is used to determine visits via unique IP-address and UserAgent.
-
Hits, such as images, CSS files, Wordpress resource files, etc are filtered to derive page counts.
-
Statistics such as per hour accounting and geographical origin are collected.
-
Top-50 charts and graphs are generated in an HTML report from the collected statistics.
There is lots of room for future improvements, e.g. creation of additional modules for new charts and graphs, possibly accounting across multiple years, use of intermediate files to speed up processing and more. In any case, the current state works well for giant log files and already provides interesting graphs. The code right now is alpha quality, i.e. ready for a technical preview but it might still have some quirks. Feedback is welcome.
The tobin source code and tobin issue tracker are hosted on Github. Python 2.7 and a number of auxiliary modules are required. Building and testing works as follows:
$ git clone https://github.com/tim-janik/tobin.git
$ make # create tobin executable
$ ./tobin -n MySiteName mysite.log
$ x-www-browser logreport/index.htmlLeave me a comment if you have issues testing it out and let me know how the report generation works for you. ;-)